

How To Create A Search Engine From Scratch
Building a search engine from scratch
![]()

Have you ever wondered what happens when you type "what is the meaning of life" into Google?
If yes, that means two things:
- We have a lot in common.
- You will probably find this article interesting.
Search engines are infinitely complex. Millions of servers are: scraping websites from the internet, storing and aggregating the information, doing huge matrix calculations and inching the world ever closer to the singularity.
Still, the basics of what a Search engine doe s is relatively simple. You give it a question in the form of a query. The search engine finds pages that are relevant for that query. A lot of factors go into deciding the relevance of a certain page for a certain query, but the most important one is:
Does the text one the page match the text that the user provided in the query.
We'll go one step above the basics, and build a fully functional full text search library in Python that replicates features of Google you probably weren't even aware existed.
What is full text search?
Full text search can be defined as being able to, in a scalable way, query for terms in a set of documents. The term is most often found as an advertised feature of a database. Let's break that down.
Document: A set of words.
Do it. Just do it. Don't let your dreams be dreams. Yesterday, you said tomorrow. So just do it. Make your dreams come true. Just do it. Some people dream of success, while you're gonna wake up and work hard at it. Nothing is impossible. You should get to the point where anyone else would quit, and you're not gonna stop there. No, what are you waiting for? Do it! Just do it! Yes you can. Just do it.
If you're tired of starting over, stop giving up.
Term: Most commonly a word in the document.
just
Token: All instances of a term in the document.
… Don't let your dreams be dreams. … Make your dreams come true. …
Query: A question in the format of a specific query language.
just do
Term just or term do .
This is not something that's easy to do with a normal database index. What a normal database index does is that it stores an ordered mapping of row values to row indexes. The typical data-structure is typically an ordered map (for example implemented with a B-Tree). It allows for efficient range and exact match queries. Meaning that it's easy to answer questions like:
What person has the username 'bob'?
How many users are between 5 and 15 years old?
Those questions are not relevant when it comes to a documents. You would never Google for the entire contents of a Wikipedia article. You are rather interested in documents that contain certain words or phrases. A normal index does not allow you to do that effectively.
That is where full text search comes in, allowing you to efficiently do the query above ("just do"), but also queries like:
just AND do
Term just and term do .
"just do"
Exact phrase "just do".
just -do
Term just but not the term do .
just -do
Term just but not the term do .
do AND "you can" -tomorrow
Term do and the phrase "you can", but not the term tomorrow.
If you want to get hands on with full text search right now, try to type the queries above into Google. These queries are all understood by Google. The most common open source search engine, used by millions of sites, Elasticsearch also understands all the queries above.
In the case of Google, it will also be using many of the query types above implicitly. For example when you search for San Fransico it will look for exact matches, even though you didn't explicitly say that you were talking about the city of San Fransico.
Google Elasticsearch
But wait, it get's better. Each document get's a score.
Scoring: Search engines assign a score to each document for a specific query.
9000.001
Elasticsearch is built on top of Lucene, which is a full text search library that uses an algorithm called tf-idf. Without going to deep into it, the document will be scored based on how many times a term appears in the document, compared to how common it is overall.
How does this work in practice?
TL;DR: First we split the document into tokens. Then we insert the tokens into an inverted-index. Lastly we use this inverted index to efficiently execute the queries.
Building a search engine is not trivial. Thousands of engineers are involved in building services like Google, Bing and Elasticsearch.
To fit the entire process into a blog post I've made some simplifications:
- Our library only supports the query types above.
- We use the simplest data-structure that will get the job done.
- We index all the data, then query it. Normal full text search libraries support whats called incremental indexing — meaning that you can add documents to the index and can query while you are indexing.
- We ignore topics like query planning, ASTs and compression.
I'm planning to write separate posts about each of those topics. The implementation should give a good understanding of how an optimized library works. For example our implementation for exact querying does the same highly optimized libraries like Lucene and Tantivy, just in a much slower way.
The pipeline
Indexing can be viewed as a pipeline, where the last step is querying.
- Documents: We start with a set of documents. Where these are comming from is outside the scope of this blog post. In my examples I use 3 motivational speeches stored on the local file system.
- Analyze: As mentioned above, we need to break the document down into terms. The most common way of doing this is getting all the words in lower case — so that is what we'll do.
- Index: This is when we insert the tokens into the data-structure we're going to query.
- Query: We convert the implicit logic in the query (given by the query language) into efficiently finding the right documents.
Visually it looks like this.
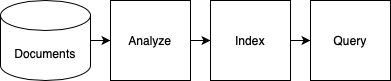
So let's get into it.
Analyze
As stated above, the goal of this step is to convert the document strings into tokens, and the method is extracting the lower case words. The method below is very primitive and does not handle a lot of cases correctly, but for demonstrative purposes it works.
def tokenize(document: str) -> List[str]:
# convert the document to lowercase
lowercase_document = document.lower()
# extract all the words using a regex
words = re.findall(r"\w+", lowercase_document)
return list(words) tokenized_documents = [tokenize(document) for document in documents] for tokenized_document in tokenized_documents:
print(tokenized_document[:3], "...", tokenized_document[-3:])
['inch', 'by', 'inch'] … ['you', 'gonna', 'do']
['just', 'do', 'it'] … ['stop', 'giving', 'up']
['the', 'pursuit', 'of'] … ['get', 'it', 'period']
Now we have the tokens for each document.
Indexing
The next step is to convert the tokens into a data-structure that can be easily queried. This is called an inverted index.
The requirements for an inverted index is that you can easily given a word figure out what documents it's in. Instantly many people will think of a HashMap. In a real search engine, the index is an ensemble of different data-structures.
inverted_index = {} for document_id, tokenized_document in enumerate(tokenized_documents):
for token_index, token in enumerate(tokenized_document):
token_position = (document_id, token_index)
if token in inverted_index:
inverted_index[token].append(token_position)
else:
inverted_index[token] = [token_position] print("just ->", inverted_index["the"])
print("do ->", inverted_index["the"])
just -> [(1, 0), (1, 5), (1, 20), (1, 28), (1, 76), (1, 82)]
do -> [(0, 94), (0, 399), (0, 455), (0, 493), (1, 1), (1, 3), (1, 6), (1, 21), (1, 29), (1, 74), (1, 77), (1, 83), (2, 15), (2, 33), (2, 44)]
The reason why we're storing the positions of each term instead of the frequency is that it allows efficient exact match queries.
Querying
We want to support the following operators:
- OR: Given that there is no operator between two terms, we assume that there is an OR relation, so given "a b" we interpret that as "a OR b".
- AND: When two terms have an "AND" operator between them we only return documents that match both terms.
- INCLUDE: If a term is prepended by a "+" we exclude all documents that don't contain that term.
- EXCLUDE: If a term is prepended by a "-" we exclude all documents that contain that term.
We also have the possibility of exact matching. Anything within quotes will be treated as a single term, and only documents that exactly match will be returned.
The algorithm I'm using is the following:
- Split the query into a list containing both the operators and terms.
- Evaluate the query from left to right in a single pass, keeping track of the current score of each document, what documents have been excluded and what documents have been included.
- In the end return the document identifiers as a list sorted by the score, with the correct documents based on inclusion and exclusion filtered out.
One thing that's missing from this algorithm is that we don't support parenthesis. That would complicate this already extremely complicated explanation even more.
Structure of the algorithm
Let's consider the following query:
do AND "you can" -tomorrow
First step is to seperate out the terms and the operators in the query.
query_expressions = re.findall(r"[\"\-\+]|[\w]+", query) ['do', 'AND', '"', 'you', 'can', '"', '-', 'tomorrow']
Next we'll initiate the global state we'll update as we process the query.
document_scores: DocumentScores = {}
excluded_document_ids: Set[DocumentId] = set()
included_document_ids: Set[DocumentId] = set() The evaluation algorithm uses a mode and a pointer. By default the mode is set to OR, but when it hit's an operand it changes it to the appropriate mode. The way a term is processed depends on the mode. Exact matches are handled in the same way as terms, except for more complicated logic for getting the score.
mode = Mode.OR
pointer = 0 while pointer < len(query_expressions):
query_expression = query_expressions[pointer]
if query_expression in MODES:
# set mode
else:
if query_expression == QUOTE:
# handle EXACT CASE
new_document_scores = ...
# set pointer to the location of the closing quote
else:
# handle TERM CASE
new_document_scores = ...
# update the global variables variables
# using new_document_scores and the mode
# AND, OR, INCLUDE, EXCLUDE
pointer += 1 # compute the final scores
# filter out based on exclusion and inclusion
Computing the scores
TERM CASE
To get the score for a term we first get all the token positions from the the inverted index.
token_positions = inverted_index[term] document_term_scores = term_scores(token_positions)
document_term_scores = {1: 10, 5: 3, 5: 3}
EXACT CASE
Parsing of exact matches is more complicated. The basic algorithm is:
- Start with the first term.
- Find all token locations that match the term.
- Compute the expected next locations. So where in the document would the next expected term be.
- While there are more terms, repeat the process above.
The actual code is more complicated, to handle various error cases, but the happy path is equivalent to this:
pointer += 1 matches = [
(document_id, token_position + 1)
for document_id, token_position in inverted_index.get(
query_expressions[pointer], []
)
] pointer += 1 while query_expressions[pointer] != QUOTE:
if not matches:
break
term = query_expressions[pointer]
matches = next_token_position_matches(inverted_index[term], matches)
pointer += 1 document_term_scores = term_scores(token_positions)
The term_scores method
The scoring method used in this example is simply the number of times a term appears in a document. The method to calculate that looks like this:
def term_scores(token_positions: TokenPositions) -> DocumentScores:
document_term_scores: DocumentScores = {}
for document_id, _ in token_positions:
if document_id in document_term_scores:
document_term_scores[document_id] += 1
else:
document_term_scores[document_id] = 1
return document_term_scores Updating the globals based on the mode
When we have computed the document_term_scores we need to merge them into the global state. How we do this depends on the mode.
OR
The OR operation is simple and just adds to the current scores.
def merge_or(current: DocumentScores, new: DocumentScores):
for document_id, score in new.items():
if document_id in current:
current[document_id] += score
else:
current[document_id] = score AND
When computing the AND we need to remove the documents that did not contain the term and only add the terms that already exist in the scores table.
def merge_and(current: DocumentScores, new: DocumentScores):
# Find the keys that are not in both.
filtered_out = set(current.keys()) ^ set(new.keys())
for document_id in list(current.keys()):
if document_id in filtered_out and document_id in current:
del current[document_id]
for document_id, score in list(new.items()):
if document_id not in filtered_out:
current[document_id] += score Above I'm using some set magic, but it's equivalent to the difference.
INCLUDE
included_document_ids.update(document_term_scores.keys()) EXCLUDE
excluded_document_ids.update(document_term_scores.keys()) Compute the results
In the end we filter out the documents that documents that should be excluded or were not explicitly included.
return list(
sorted(
(
(document_id, score)
for document_id, score in document_scores.items()
if (no_include_in_query or document_id in included_document_ids)
and document_id not in excluded_document_ids
),
key=lambda x: -x[1],
)
) The result is the following:
[(1, 'THE PURSUIT OF HAPPYNESS', 5)] Some other examples.
just do
[(2, 'JUST DO IT', 14), (0, 'INCH BY INCH', 4), (1, 'THE PURSUIT OF HAPPYNESS', 3)]
just AND do
[(2, 'JUST DO IT', 14)]
"just do" AND it
[(2, 'JUST DO IT', 15)]
+"just do" AND tomorrow
[(2, 'JUST DO IT', 7)]
-just do
[(0, 'INCH BY INCH', 4), (1, 'THE PURSUIT OF HAPPYNESS', 3)] So we have successfully replicated the behavior of Google search in 100 lines of code.
Benchmarks
Using a larger text dataset of all the works of Shakespeare we get the following performance numbers.
query_index function took 1.389 ms
just do
[(15, 'othello', 229), (37, 'hamlet', 162), (32, 'troilus_cressida', 149)]
query_index function took 1.336 ms
just AND do
[(15, 'othello', 229), (37, 'hamlet', 162), (32, 'troilus_cressida', 149)]
query_index function took 3.134 ms
"just do" AND it
[]
query_index function took 0.737 ms
+"just do" AND tomorrow
[]
query_index function took 0.901 ms
-just do
[(6, 'coriolanus', 130), (20, 'midsummer', 107), (26, 'lll', 95)]
query_index function took 12.303 ms
do AND "you can" -tomorrow
[(37, 'hamlet', 161), (32, 'troilus_cressida', 146), (18, 'cleopatra', 127) Comparable performance of iterating through the tokens for the 'just do' is 101ms, so our approach is 100x faster.
Summary
The goal of this post was to give a deeper understanding of how a search engine works "under the hood". In future blog posts I want to go further into the following topics:
- Analysis: How we can use NLP and other techniques to generate better tokens.
- Indexing: What data structures are good and why.
- Querying: How can we optimize queries? How can we give better scores?
- Incremental indexing: How do we index documents and make updates available in real-time.
- Distributed search: What are the typical patterns used for scaling out to multiple machines.
The code for the project is here:
Cool projects:
How To Create A Search Engine From Scratch
Source: https://halvorboe.medium.com/building-a-search-engine-from-scratch-e102ac39855a
Posted by: smallhealf1997.blogspot.com
0 Response to "How To Create A Search Engine From Scratch"
Post a Comment